此前发布过关于 aaencode 的混淆编码,此篇文章继续说同作者的 jjencode 混淆编码的具体过程。
介绍
首先是 jjencode 的作者提供的编码测试页:http://utf-8.jp/public/jjencode.html
可以将任何合法的 JavaScript 代码进行编码,首先我们可以简单测试将以下代码进行编码。
编码前:
alert("Hello, JavaScript" )
编码后:
$=~[];$={___:++$,$$$$:(![]+"")[$],__$:++$,$_$_:(![]+"")[$],_$_:++$,$_$$:({}+"")[$],$$_$:($[$]+"")[$],_$$:++$,$$$_:(!""+"")[$],$__:++$,$_$:++$,$$__:({}+"")[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+"")[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+"")[$.__$])+((!$)+"")[$._$$]+($.__=$.$_[$.$$_])+($.$=(!""+"")[$.__$])+($._=(!""+"")[$._$_])+$.$_[$.$_$]+$.__+$._$+$.$;$.$$=$.$+(!""+"")[$._$$]+$.__+$._+$.$+$.$$;$.$=($.___)[$.$_][$.$_];$.$($.$($.$$+"\""+$.$_$_+(![]+"")[$._$_]+$.$$$_+"\\"+$.__$+$.$$_+$._$_+$.__+"(\\\"\\"+$.__$+$.__$+$.___+$.$$$_+(![]+"")[$._$_]+(![]+"")[$._$_]+$._$+",\\"+$.$__+$.___+"\\"+$.__$+$.__$+$._$_+$.$_$_+"\\"+$.__$+$.$$_+$.$$_+$.$_$_+"\\"+$.__$+$._$_+$._$$+$.$$__+"\\"+$.__$+$.$$_+$._$_+"\\"+$.__$+$.$_$+$.__$+"\\"+$.__$+$.$$_+$.___+$.__+"\\\"\\"+$.$__+$.___+")"+"\"")())();
可见,编码后的 JS 也是很有意思,仅由符号组成的 JS 代码。
混淆过程
通过源代码,我们可以看到具体将 JS 进行编码的函数过程,如下所示:
function jjencode( gv, text )
{
var r="";
var n;
var t;
var b=[ "___", "__$", "_$_", "_$$", "$__", "$_$", "$$_", "$$$", "$___", "$__$", "$_$_", "$_$$", "$$__", "$$_$", "$$$_", "$$$$", ];
var s = "";
for( var i = 0; i < text.length; i++ ){
n = text.charCodeAt( i );
if( n == 0x22 || n == 0x5c ){
s += "\\\\\\" + text.charAt( i ).toString(16);
}else if( (0x21 <= n && n <= 0x2f) || (0x3A <= n && n <= 0x40) || ( 0x5b <= n && n <= 0x60 ) || ( 0x7b <= n && n <= 0x7f ) ){
//}else if( (0x20 <= n && n <= 0x2f) || (0x3A <= n == 0x40) || ( 0x5b <= n && n <= 0x60 ) || ( 0x7b <= n && n <= 0x7f ) ){
s += text.charAt( i );
}else if( (0x30 <= n && n <= 0x39 ) || (0x61 <= n && n <= 0x66 ) ){
if( s ) r += "\"" + s +"\"+";
r += gv + "." + b[ n < 0x40 ? n - 0x30 : n - 0x57 ] + "+";
s="";
}else if( n == 0x6c ){ // 'l'
if( s ) r += "\"" + s + "\"+";
r += "(![]+\"\")[" + gv + "._$_]+";
s = "";
}else if( n == 0x6f ){ // 'o'
if( s ) r += "\"" + s + "\"+";
r += gv + "._$+";
s = "";
}else if( n == 0x74 ){ // 'u'
if( s ) r += "\"" + s + "\"+";
r += gv + ".__+";
s = "";
}else if( n == 0x75 ){ // 'u'
if( s ) r += "\"" + s + "\"+";
r += gv + "._+";
s = "";
}else if( n < 128 ){
if( s ) r += "\"" + s;
else r += "\"";
r += "\\\\\"+" + n.toString( 8 ).replace( /[0-7]/g, function(c){ return gv + "."+b[ c ]+"+" } );
s = "";
}else{
if( s ) r += "\"" + s;
else r += "\"";
r += "\\\\\"+" + gv + "._+" + n.toString(16).replace( /[0-9a-f]/gi, function(c){ return gv + "."+b[parseInt(c,16)]+"+"} );
s = "";
}
}
if( s ) r += "\"" + s + "\"+";
r =
gv + "=~[];" +
gv + "={___:++" + gv +",$$$$:(![]+\"\")["+gv+"],__$:++"+gv+",$_$_:(![]+\"\")["+gv+"],_$_:++"+
gv+",$_$$:({}+\"\")["+gv+"],$$_$:("+gv+"["+gv+"]+\"\")["+gv+"],_$$:++"+gv+",$$$_:(!\"\"+\"\")["+
gv+"],$__:++"+gv+",$_$:++"+gv+",$$__:({}+\"\")["+gv+"],$$_:++"+gv+",$$$:++"+gv+",$___:++"+gv+",$__$:++"+gv+"};"+
gv+".$_="+
"("+gv+".$_="+gv+"+\"\")["+gv+".$_$]+"+
"("+gv+"._$="+gv+".$_["+gv+".__$])+"+
"("+gv+".$$=("+gv+".$+\"\")["+gv+".__$])+"+
"((!"+gv+")+\"\")["+gv+"._$$]+"+
"("+gv+".__="+gv+".$_["+gv+".$$_])+"+
"("+gv+".$=(!\"\"+\"\")["+gv+".__$])+"+
"("+gv+"._=(!\"\"+\"\")["+gv+"._$_])+"+
gv+".$_["+gv+".$_$]+"+
gv+".__+"+
gv+"._$+"+
gv+".$;"+
gv+".$$="+
gv+".$+"+
"(!\"\"+\"\")["+gv+"._$$]+"+
gv+".__+"+
gv+"._+"+
gv+".$+"+
gv+".$$;"+
gv+".$=("+gv+".___)["+gv+".$_]["+gv+".$_];"+
gv+".$("+gv+".$("+gv+".$$+\"\\\"\"+" + r + "\"\\\"\")())();";
return r;
}
使用方式即是:
jjencode( '$', 'alert("Hello, JavaScript" )' )
参数 1,就类似于混淆代码中的一个全局变量,参数 2 就是具体要进行混淆的原 JS 代码。
代码解析
接下来我们将这段 JS 函数进行解析,将混淆后的代码进行阅读,以便更好的理解其编码的思路。
对比混淆
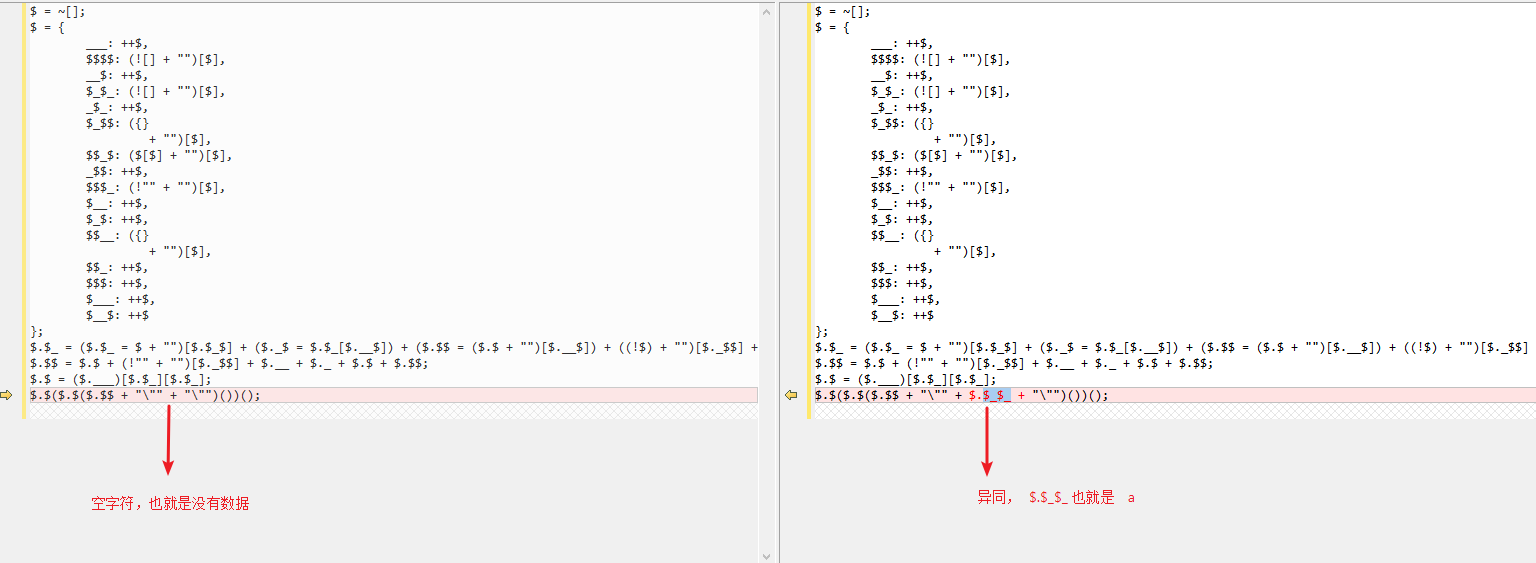
首先编码一个“空文本代码”混淆后的代码,以及一个 JS 仅有字符“a”混淆后的代码,并将其格式化对比查看。
左边是由空字符构成的混淆后代码,右边是由字符 a 构成的混淆后代码。
由此我们基本可以看出其中多出来的部分就是具体我们原本的 JS 代码。
为了测试,我们此次混淆一段代码并将其执行,如下:

其实际就是:
console.log("tokyo")
逐步分析
我们将混淆后的代码进行逐行执行,了解其到底做了哪些事情。
根据下图,可以看到其的运行过程。
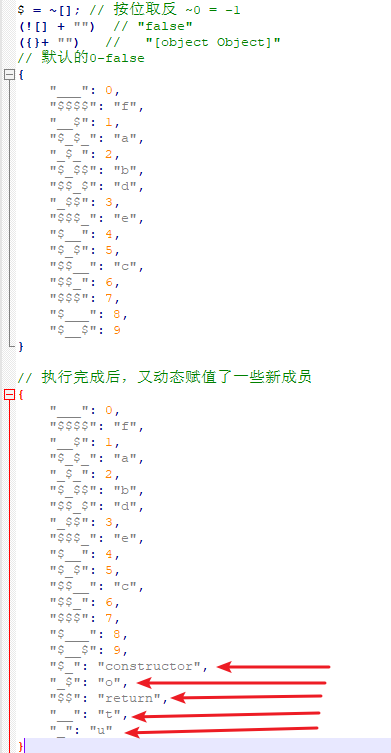
首先,初始化赋值将 ~[] 赋值到 $ 上,而这个 $ 就是我们之前说的哪个全局变量,也可以可定义的。
~[] 实际执行的是,初始化一个空数组,再将其按位取反即实际是 按位取反的 0,即:$ = ~0 = -1(当然他这边也可以直接写作 ~0 ,但就不能很好的达到混淆的效果,毕竟混淆后是仅由符号组成的代码)
第二句,也可以很明显看到这个数组对象中存储的值是由 0-10 a-f 之间的字符,也就正好完整的表示了十六进制的所有字符。
第三句,实际上是按照第二句赋值后的混淆数组,构成一个 constructor 字符串。
第四句,构造一个 return 字符串
第五句,构造一个匿名函数体
第六句,将我们原本的代码混淆后,作为参数传递给前面的匿名参数里,并执行。

constructor
在这里需要说明下,其中的构造函数执行原理。并非通过 eval,而是通过 constructor(构造方法)。
因 JS 万物皆对象,所以其中的 Number 也是对象,0 也是对象、1 也是对象、“123”是 String 对象,……都是对象。
所以,这行代码是这样实现一个空函数体的。
($.___) == 0
[$.$_] 其中的 $.$_ 接上面代码,也就是 constructor 字符串
那么拼接到一起就是 0["constructor"]["constructor"] 也等同于下面这一行内容
$.$ = ($.___)[$.$_][$.$_];
也等同于 eval
最终执行
那么,到了最后一行,也就是执行了。将已经编好的代码扔到匿名函数里进行执行。(注意:最后有一个()进行自执行)
# f( "return" + '"' + "你的代码" + '"') 这一步构造了一个函数体
# $.$($.$($.$$ + "\"" + "\"")()) 这一步构造一个新的函数体,参数是上一步的函数体,也就是 匿名函数。
# $.$($.$($.$$ + "\"" + "\"")())(); 最后再通过()调用自执行。
# 最终如下
$.$($.$($.$$ + "\"" + "\"")())();
此时,我们的代码算是执行完毕了。不过此时,原本构造的$ 键值对数组,已经改变了,在构造 constructor 过程及之后,又附加了几个值。
引用结构
下图简单批注,可对比看到,也就为了后面的运行引用做准备。
源码分析
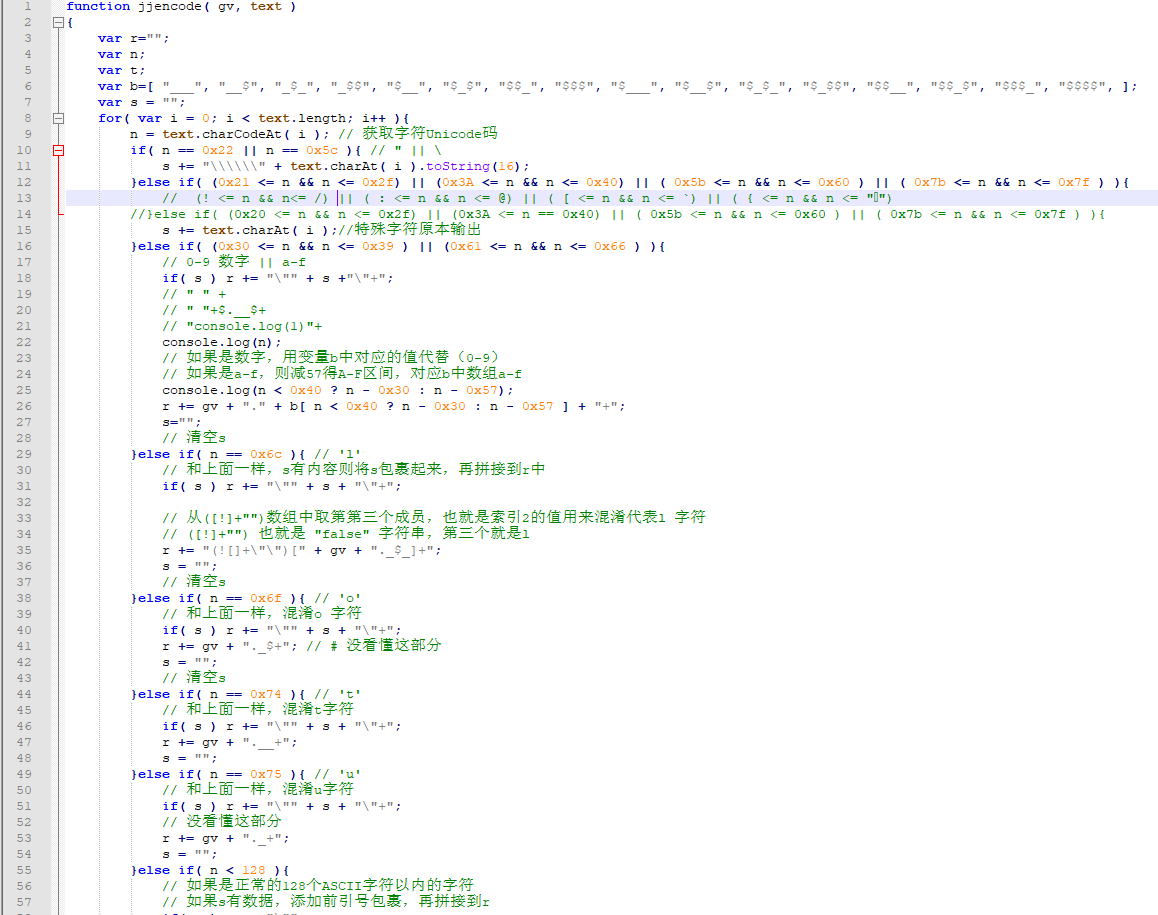
运行原理大致我们看明白了,接下来来分析下源代码,看他是如何将代码编码混淆的。
下图是我简单批注后的源代码,也是第一次分析时留下的注释,比较散乱。
逐步分析
简单看过,之后我们逐步分下下执行过程。
首先可以看到,有一个固定的声明数组:b (简称:b 数组)
b 数组中,是固定的一些由符号组成的值,也就对应后面的 0-9 a-f 的区间,数一下,正好是 16 位。
for 循环是将 text(我们的原代码),逐个字符开始进行编码。
模拟走一遍流程,如最初时我们将 a 进行编码,text.charCodeAt( i ) 即获得 a 的 Unicode 编码,也就是 97。
现在:n = 97 = a
接下来进入判断流程,如果 n 等于 0x22 或者等于 0x5c,就需要将其添加反斜杠进行转义保存,其值也需要转换值十六进制。
如果是 a,则会将其存储为 "\\\61"
> "\\\\\\" + "a".charCodeAt(0).toString(16);
< "\\\61"
很显然这里我们的 a 不符合判断条件,判断条件中的 0x22 和 0x5c 分别对应的 ASCII 码是 "(双引号)\ (反斜杠)。也是为了拼接时的代码冲突,才将其转义。
此时我们通过查看对照 ASCII 码,更好的理解分析其中的判断逻辑。
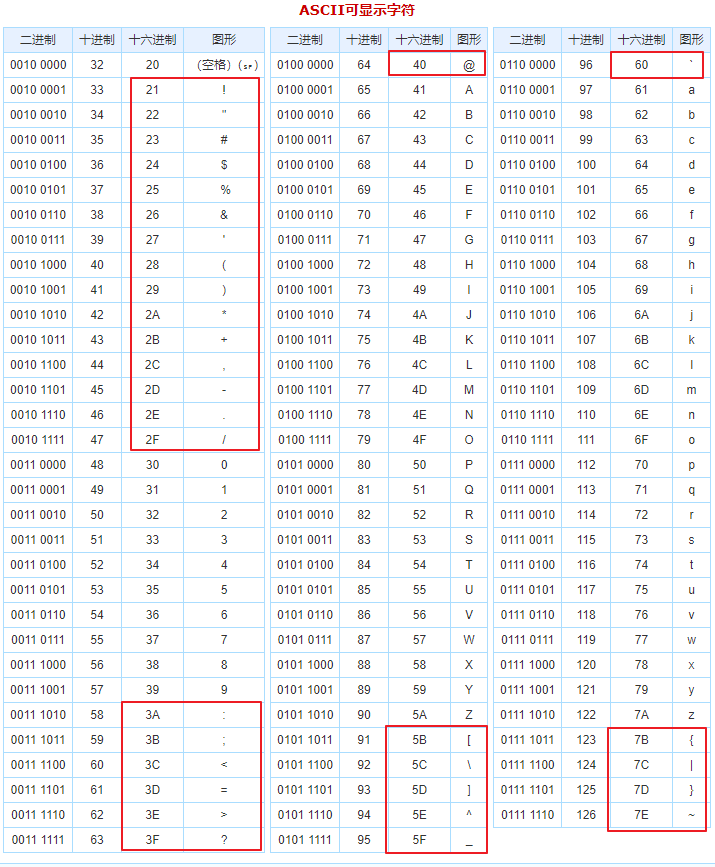
第二个判断是也在图中标注了,如果是特殊字符,则原样记录。
第三个判断,将 0-F 之间的数据用 b 数组很好的进行引用代替。
第四、五、六、七个判断分别对这个几个字符(l o t u )特殊对待进行转码。
第八个判断,如果是字符是在合法的 ASCII(128 字符)以内,则将其转换为 8 进制存储,并将其的每一位替换成 b 数组中的字符引用。
举例:我们刚才的 a 字符,十进制 97,八进制就是 141,那么存储起来就是
> "\\\141"
< "\a"
混淆后就是这般:
> "\\\\\"+" + "a".charCodeAt(0).toString( 8 ).replace( /[0-7]/g, function(c){ return "$" + "."+b[ c ]+"+" } );
< "\\"+$.__$+$.$__+$.__$+"
最后一个 else 中的就是替换其他双字节字符,如汉字:
> "\\\\\"+" + "$" + "._+" + "中国".charCodeAt(0).toString(16).replace( /[0-9a-f]/gi, function(c){ return "$" + "."+b[parseInt(c,16)]+"+"} );
< "\\"+$._+$.$__+$.$$$_+$._$_+$.$$_$+"

经过一轮混淆判断之后,将混淆的内容存储到 r 中,s 则类似于一个缓冲区。
声明函数体
后面则是我们最开始分析的编码后的代码。
这里主要工作是构造一个函数体结构为后面执行做准备。
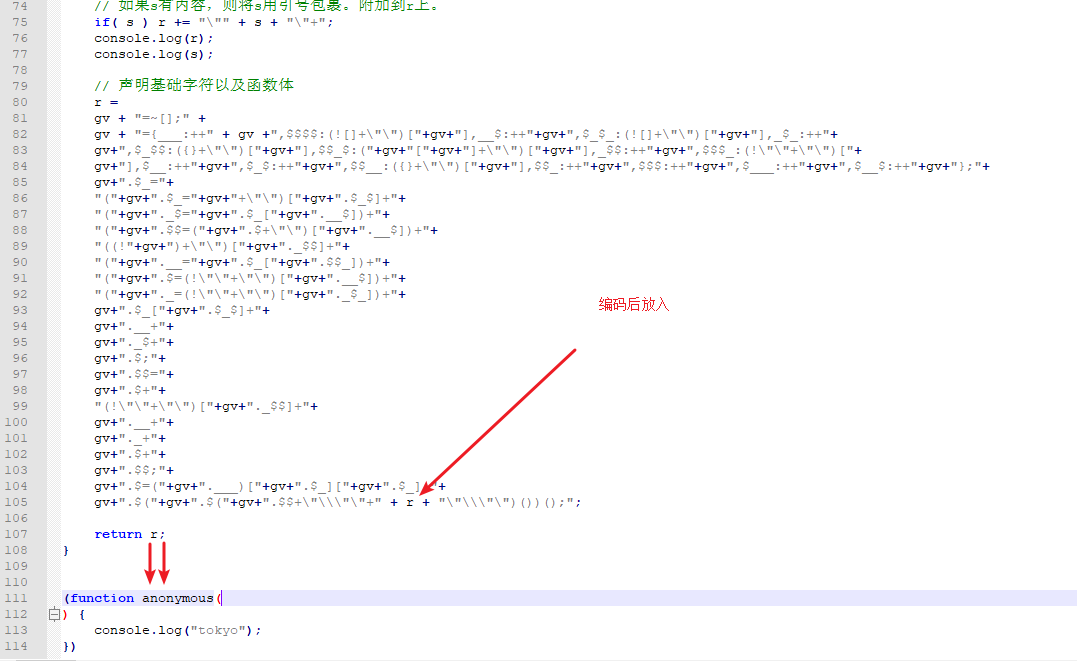
可以看到声明函数体后,将我们编码后的 r 作为参数传给函数体并自执行。也等同于最后面的匿名函数。
这个函数的声明过程到这里就执行完毕了!
混淆变体
如果此时你想,将代码稍微改改,变换一下混淆的引用元素或者混淆方法,那也是可以的。
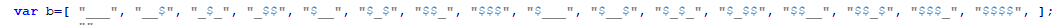
我们将最开始的 b 数组中对应的 0-F 区间引用名,逐个替换。
如下:

当然还有后面动态添加的 o、t、u、constructor、return、f 函数等一一用新的字符替换。
即最开始的 b 数组 我们这样定义:
var b=[ "富强", "民主", "文明", "和谐", "自由", "平等", "公正", "法治", "爱国", "敬业", "诚信", "友善", "富强民主", "文明和谐", "自由平等", "公正法治", ];
函数体部分:

图中的部分代码没有替换干净,如:![]+"",是因为截图时是之前的了,这里都是可以替换的。
参考下表:
(!(富强+富强)+"") = (![] + "") = "false"
(!(富强-富强)+"") = (!"" + "") = "true"
({富强:富强}+"") = ({}+ "") = "[object Object]"
这里用"富强"的位置可以换做其他任意字符,之所以选择"富强"原因而不用其他字符的原因,是为了选择出现率最高让代码更混乱。
替换后的代码并编码如下:
富强 = ~"富强";
富强 = {
富强: ++富强,
公正法治: (!!(富强 - 富强)+"")[富强],
民主: ++富强,
诚信: (!!(富强 - 富强)+"")[富强],
文明: ++富强,
友善: ({富强:富强}+"")[富强],
文明和谐: (富强[富强] + "")[富强],
和谐: ++富强,
自由平等: (!(富强-富强)+"")[富强],
自由: ++富强,
平等: ++富强,
富强民主: ({富强:富强}+"")[富强],
公正: ++富强,
法治: ++富强,
爱国: ++富强,
敬业: ++富强
};
富强.民主和谐 = (富强.民主和谐 = 富强 + "")[富强.平等] + (富强.爱国敬业 = 富强.民主和谐[富强.民主]) + (富强.文明自由 = (富强.和谐平等 + "")[富强.民主]) + ((!富强) + "")[富强.和谐] + (富强.诚信友善 = 富强.民主和谐[富强.公正]) + (富强.和谐平等 = (!(富强-富强)+"")[富强.民主]) + (富强.富强文明 = (!(富强-富强)+"")[富强.文明]) + 富强.民主和谐[富强.平等] + 富强.诚信友善 + 富强.爱国敬业 + 富强.和谐平等;
富强.文明自由 = 富强.和谐平等 + (!(富强-富强)+"")[富强.和谐] + 富强.诚信友善 + 富强.富强文明 + 富强.和谐平等 + 富强.文明自由;
富强.和谐平等 = (富强.富强)[富强.民主和谐][富强.民主和谐];
富强.和谐平等(富强.和谐平等(富强.文明自由 + "\"" + 富强.富强民主 + 富强.爱国敬业 + "\\" + 富强.民主 + 富强.平等 + 富强.公正 + "\\" + 富强.民主 + 富强.公正 + 富强.和谐 + 富强.爱国敬业 + (!(富强+富强)+"")[富强.文明] + 富强.自由平等 + "." + (!(富强+富强)+"")[富强.文明] + 富强.爱国敬业 + "\\" + 富强.民主 + 富强.自由 + 富强.法治 + "(" + 富强.民主 + 富强.民主 + 富强.民主 + 富强.民主 + ")" + "\"")())();
压缩后如下:
富强=~"富强";富强={富强:++富强,公正法治:(!!(富强-富强)+"")[富强],民主:++富强,诚信:(!!(富强-富强)+"")[富强],文明:++富强,友善:({富强:富强}+"")[富强],文明和谐:(富强[富强]+"")[富强],和谐:++富强,自由平等:(!(富强-富强)+"")[富强],自由:++富强,平等:++富强,富强民主:({富强:富强}+"")[富强],公正:++富强,法治:++富强,爱国:++富强,敬业:++富强};富强.民主和谐=(富强.民主和谐=富强+"")[富强.平等]+(富强.爱国敬业=富强.民主和谐[富强.民主])+(富强.文明自由=(富强.和谐平等+"")[富强.民主])+((!富强)+"")[富强.和谐]+(富强.诚信友善=富强.民主和谐[富强.公正])+(富强.和谐平等=(!(富强-富强)+"")[富强.民主])+(富强.富强文明=(!(富强-富强)+"")[富强.文明])+富强.民主和谐[富强.平等]+富强.诚信友善+富强.爱国敬业+富强.和谐平等;富强.文明自由=富强.和谐平等+(!(富强-富强)+"")[富强.和谐]+富强.诚信友善+富强.富强文明+富强.和谐平等+富强.文明自由;富强.和谐平等=(富强.富强)[富强.民主和谐][富强.民主和谐];富强.和谐平等(富强.和谐平等(富强.文明自由+"\""+富强.富强民主+富强.爱国敬业+"\\"+富强.民主+富强.平等+富强.公正+"\\"+富强.民主+富强.公正+富强.和谐+富强.爱国敬业+(!(富强+富强)+"")[富强.文明]+富强.自由平等+"."+(!(富强+富强)+"")[富强.文明]+富强.爱国敬业+"\\"+富强.民主+富强.自由+富强.法治+"("+富强.民主+富强.民主+富强.民主+富强.民主+")"+"\"")())();
运行效果:

这种方式用来混淆 JS 代码,并不能防止破解,只能骗过不了解 JS 的新手,比较适用于的场景就是防止无脑爬虫抓取页面信息。以及配合其他混淆规则效果会更好。
最后粘贴一份我更改过后的 JS 混淆过程代码,因用了中文,后面的双字节支持会有问题,也没来得及修正。所以双字节会报错。
// 富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善
// _$ = o = 爱国敬业
// __ = t = 诚信友善
// _ = u = 富强文明
// $_ = constructor = 民主和谐
// $$ = return = 文明自由
// $ = f 函数 = 和谐平等
function jjencode( gv, text )
{
var r="";
var n;
var t;
var b=[ "___", "__$", "_$_", "_$$", "$__", "$_$", "$$_", "$$$", "$___", "$__$", "$_$_", "$_$$", "$$__", "$$_$", "$$$_", "$$$$", ];
var b=[ "富强", "民主", "文明", "和谐", "自由", "平等", "公正", "法治", "爱国", "敬业", "诚信", "友善", "富强民主", "文明和谐", "自由平等", "公正法治", ];
var s = "";
for( var i = 0; i < text.length; i++ ){
n = text.charCodeAt( i ); // 获取字符 Unicode 码
if( n == 0x22 || n == 0x5c ){ // " || \
s += "\\\\\\" + text.charAt( i ).toString(16);
}else if( (0x21 <= n && n <= 0x2f) || (0x3A <= n && n <= 0x40) || ( 0x5b <= n && n <= 0x60 ) || ( 0x7b <= n && n <= 0x7f ) ){
// (! <= n && n<= /) || ( : <= n && n <= @) || ( [ <= n && n <= `) || ( { <= n && n <= "")
//}else if( (0x20 <= n && n <= 0x2f) || (0x3A <= n == 0x40) || ( 0x5b <= n && n <= 0x60 ) || ( 0x7b <= n && n <= 0x7f ) ){
s += text.charAt( i );//特殊字符原本输出
}else if( (0x30 <= n && n <= 0x39 ) || (0x61 <= n && n <= 0x66 ) ){
// 0-9 数字 || a-f
if( s ) r += "\"" + s +"\"+";
// " " +
// " "+$.__$+
// "console.log(1)"+
console.log(n);
// 如果是数字,用变量 b 中对应的值代替(0-9)
// 如果是 a-f,则减 57 得 A-F 区间,对应 b 中数组 a-f
console.log(n < 0x40 ? n - 0x30 : n - 0x57);
r += gv + "." + b[ n < 0x40 ? n - 0x30 : n - 0x57 ] + "+";
s="";
// 清空 s
}else if( n == 0x6c ){ // 'l'
// 和上面一样,s 有内容则将 s 包裹起来,再拼接到 r 中
if( s ) r += "\"" + s + "\"+";
// 从([!]+"")数组中取第第三个成员,也就是索引 2 的值用来混淆代表 l 字符
// ([!]+"") 也就是 "false" 字符串,第三个就是 l
r += "(![]+\"\")[" + gv + ".文明]+";
s = "";
// 清空 s
}else if( n == 0x6f ){ // 'o'
// 和上面一样,混淆 o 字符
if( s ) r += "\"" + s + "\"+";
r += gv + ".爱国敬业+"; // # 没看懂这部分
s = "";
// 清空 s
}else if( n == 0x74 ){ // 't'
// 和上面一样,混淆 t 字符
if( s ) r += "\"" + s + "\"+";
r += gv + ".诚信友善+";
s = "";
}else if( n == 0x75 ){ // 'u'
// 和上面一样,混淆 u 字符
if( s ) r += "\"" + s + "\"+";
// 没看懂这部分
r += gv + ".富强文明+";
s = "";
}else if( n < 128 ){
// 如果是正常的 128 个 ASCII 字符以内的字符
// 如果 s 有数据,添加前引号包裹,再拼接到 r
if( s ) r += "\"" + s;
// 否则直接给 r 拼接引号(可能结束引号,也可能是开始)
else r += "\"";
// 拼接转义符 和引号, 再将字符取 8 进制,且将 8 进制的数字用 b 数组中的 0-7 代替表示。
r += "\\\\\"+" + n.toString( 8 ).replace( /[0-7]/g, function(c){ return gv + "."+b[ c ]+"+" } );
s = "";// 清空 s
}else{
// 其他大于 128 的字符,进行引号包裹
if( s ) r += "\"" + s;
else r += "\"";
// 拼接转义符和引号,再拼接一个 b 数组中的_+( u ), 然后将字符码转换到 16 进制,再将 0-f 的数据用 b 数组代替表示。
r += "\\\\\"+" + gv + "._+" + n.toString(16).replace( /[0-9a-f]/gi, function(c){ return gv + "."+b[parseInt(c,16)]+"+"} );
s = "";
// 清空 s
}
}
// 如果 s 有内容,则将 s 用引号包裹。附加到 r 上。
if( s ) r += "\"" + s + "\"+";
console.log(r);
console.log(s);
// 声明基础字符以及函数体
r =
gv + "=~\"富强\";" +
gv + "={富强:++" + gv +",公正法治:(![]+\"\")["+gv+"],民主:++"+gv+",诚信:(![]+\"\")["+gv+"],文明:++"+
gv+",友善:({}+\"\")["+gv+"],文明和谐:("+gv+"["+gv+"]+\"\")["+gv+"],和谐:++"+gv+",自由平等:(!\"\"+\"\")["+
gv+"],自由:++"+gv+",平等:++"+gv+",富强民主:({}+\"\")["+gv+"],公正:++"+gv+",法治:++"+gv+",爱国:++"+gv+",敬业:++"+gv+"};"+
gv+".民主和谐="+
"("+gv+".民主和谐="+gv+"+\"\")["+gv+".平等]+"+
"("+gv+".爱国敬业="+gv+".民主和谐["+gv+".民主])+"+
"("+gv+".文明自由=("+gv+".和谐平等+\"\")["+gv+".民主])+"+
"((!"+gv+")+\"\")["+gv+".和谐]+"+
"("+gv+".诚信友善="+gv+".民主和谐["+gv+".公正])+"+
"("+gv+".和谐平等=(!\"\"+\"\")["+gv+".民主])+"+
"("+gv+".富强文明=(!\"\"+\"\")["+gv+".文明])+"+
gv+".民主和谐["+gv+".平等]+"+
gv+".诚信友善+"+
gv+".爱国敬业+"+
gv+".和谐平等;"+
gv+".文明自由="+
gv+".和谐平等+"+
"(!\"\"+\"\")["+gv+".和谐]+"+
gv+".诚信友善+"+
gv+".富强文明+"+
gv+".和谐平等+"+
gv+".文明自由;"+
gv+".和谐平等=("+gv+".富强)["+gv+".民主和谐]["+gv+".民主和谐];"+
gv+".和谐平等("+gv+".和谐平等("+gv+".文明自由+\"\\\"\"+" + r + "\"\\\"\")())();";
return r;
}
还有一份原作者的 ppt 可以阅览一下:http://utf-8.jp/public/20090710/jjencode.pps
如果有更好的 JS 混淆编码方式也欢迎留言和我交流!

